In der Welt der Unternehmensführung und -planung sind datengestützte Entscheidungen von entscheidender Bedeutung. Insbesondere in komplexen Systemen wie der Supply Chain ist Transparenz über Daten unerlässlich, um effektive Entscheidungen treffen zu können. Ein zentrales Problem, dem Unternehmen gegenüberstehen, ist der sogenannte Bullwhip-Effekt, der zu erheblichen Störungen in der Lieferkette führen kann. Hier werden wir den Bullwhip-Effekt genauer betrachten und diskutieren, wie datengesteuerte Ansätze helfen können, ihn zu managen.
Warum sind transparente Daten in der Supply Chain entscheidend?
Könnten wir klar sehen, was in der Supply Chain passiert, könnten wir bessere Entscheidungen treffen. Solange wir das große Ganze nicht sehen, entscheiden wir jedoch immer aus einer momentanen Analyse des Umfelds.
In der heutigen dynamischen Geschäftsumgebung ist es deshalb unerlässlich, klar zu sehen, was in der Lieferkette geschieht. Denn wenn Unternehmen Entscheidungen basierend auf einer begrenzten Analyse ihres Umfelds oder Annahmen treffen, kann diese Intransparenz und Unsichtbarkeit vor allem in der Supply Chain zum Bullwhip-Effekt führen.
Was ist der Bullwhip-Effekt?
Der Bullwhip-Effekt, auch bekannt als Peitscheneffekt, beschreibt ein Phänomen in Lieferketten, bei dem kleine Änderungen in der Nachfrage zu großen Schwankungen in den Bestellmengen führen, die sich von der tatsächlichen Nachfrage unterscheiden. Der Name leitet sich von der Idee ab, dass kleine Bewegungen am Ende der Peitsche zu großen Bewegungen an der Spitze führen.
Der Bullwhip-Effekt tritt aufgrund verschiedener Faktoren auf, darunter:
- Verzögerte Kommunikation: Informationen über die tatsächliche Nachfrage werden nur verzögert oder ungenau übermittelt, daraus resultiert ein Ungleichgewicht zwischen Angebot und Nachfrage.
- Bestellzyklen und Sicherheitsbestände: Unternehmen reagieren auf unvorhersehbare Nachfrageänderungen, indem sie ihre Bestellzyklen anpassen oder Sicherheitsbestände aufbauen. Dies kann zu übermäßigen Bestellungen führen, die die tatsächliche Nachfrage überschreiten.
- Preisaktionen und Aktionsangebote: Rabatte und Sonderangebote können Kunden dazu veranlassen, mehr zu kaufen, als sie tatsächlich benötigen. Dadurch steigt die Nachfrage temporär.
- Batch-Bestellungen und Verhandlungen: Lieferanten erhalten oft unregelmäßige und unvorhersehbare Bestellungen von ihren Kunden, was zu Schwankungen in der Produktion führt.
Die Auswirkungen des Bullwhip-Effekts können schwerwiegend sein und zu einer ineffizienten Nutzung von Ressourcen, übermäßigen Lagerbeständen, Lieferengpässen und höheren Kosten entlang der gesamten Lieferkette führen. Ein wichtiger Ansatz, um den Bullwhip-Effekt zu vermeiden, ist deshalb der Einsatz von datengesteuerten Analysemethoden, um mehr Transparenz zu schaffen.
Data-Driven Decision-Making: Wie können transparente Daten den Bullwhip-Effekt vermeiden?
Um den Bullwhip-Effekt effektiv zu managen, ist es entscheidend, transparente Daten in der gesamten Lieferkette zu schaffen. Dies erfordert einen ganzheitlichen Ansatz, der verschiedene Datenquellen integriert und sie in einen sinnvollen Kontext setzt, um schließlich zweckgebundene Analyseergebnisse herauszuziehen.
So wird Data-Driven Decision Making (DDDM) ermöglicht. DDDM bezeichnet den Prozess, bei dem Entscheidungen auf Basis von Daten und Fakten getroffen werden, anstatt auf Intuition, Annahmen oder Erfahrung. Durch die Analyse von Daten können Unternehmen Trends identifizieren, Muster erkennen und fundierte Entscheidungen treffen, die auf objektiven Informationen basieren. Mit dieser Art der datengestützten Entscheidungsfindung können bessere Ergebnisse erzielt und Risiken minimiert werden.
Das Grundprinzip dabei ist, die Daten aus dem Forecasting, die womöglich in Euro pro x angegeben sind, in relevante Daten für die jeweilige Business Unit zu übersetzen, wie beispielsweise Arbeitskraft oder Zeit pro Produkt.
Für diesen Prozess werden Pipelines aufgebaut, um Datenquellen an ein Data Warehouse anzubinden, in dem die Daten gesammelt, sortiert und für die Analyse vorbereitet werden. Dies ermöglicht es Unternehmen, einen umfassenden Überblick über ihre Lieferkette zu erhalten und fundierte Entscheidungen zu treffen.
Darüber hinaus ist es wichtig, den Datenfluss zwischen den verschiedenen Akteuren in der Lieferkette zu verbessern und sicherzustellen, dass relevante Informationen effektiv kommuniziert werden. Dies kann durch die Integration von Datenanalysen und Prognosetechniken erreicht werden, die es Unternehmen ermöglichen, die Nachfrage genauer vorherzusagen und ihre Bestellungen entsprechend anzupassen.
In der Welt der Unternehmensführung und -planung sind datengestützte Entscheidungen von entscheidender Bedeutung. Insbesondere in komplexen Systemen wie der Supply Chain ist Transparenz über Daten unerlässlich, um effektive Entscheidungen treffen zu können. Ein zentrales Problem, dem Unternehmen gegenüberstehen, ist der sogenannte Bullwhip-Effekt, der zu erheblichen Störungen in der Lieferkette führen kann. Hier werden wir den Bullwhip-Effekt genauer betrachten und diskutieren, wie datengesteuerte Ansätze helfen können, ihn zu managen.
Warum sind transparente Daten in der Supply Chain entscheidend?
Könnten wir klar sehen, was in der Supply Chain passiert, könnten wir bessere Entscheidungen treffen. Solange wir das große Ganze nicht sehen, entscheiden wir jedoch immer aus einer momentanen Analyse des Umfelds.
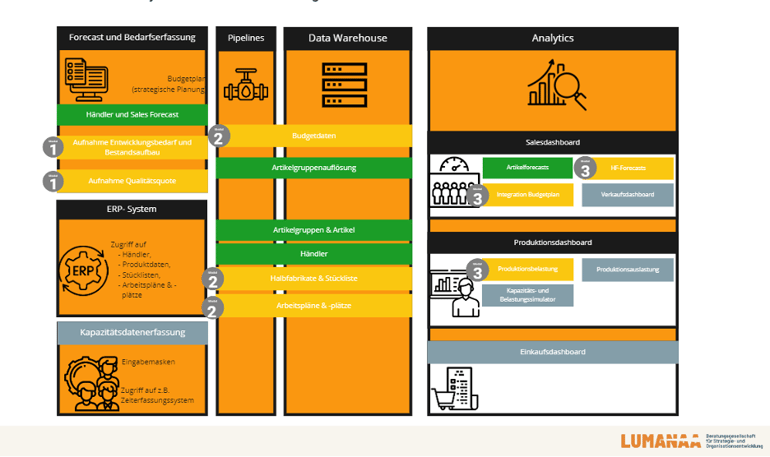
Abbildung 1: Beispiel: Überblick über das System, in das das Data Warehouse eingebunden ist und die Entwicklungsbausteine
Technische Perspektive: Entwicklung eines modernen Data Stacks
Um datengestützte Entscheidungen treffen zu können, hat man bereits in den 70er und 80er Jahren damit angefangen, sogenannte Data Warehouses zu bauen, um Daten besser auswerten zu können. Data Warehouses sind sehr strukturiert und folgen einem rigiden Schema. Das schafft effizient, ist allerdings auch durch einen Mangel an Flexibilität gekennzeichnet.
Um die Flexibilität zu erhöhen, wurden deshalb zusätzlich Data Lakes gebaut, in die Daten einfach eingespeichert werden können. Die Abbildung unten zeigt die Anbindung des Data Lakes an das Data Warehouse.
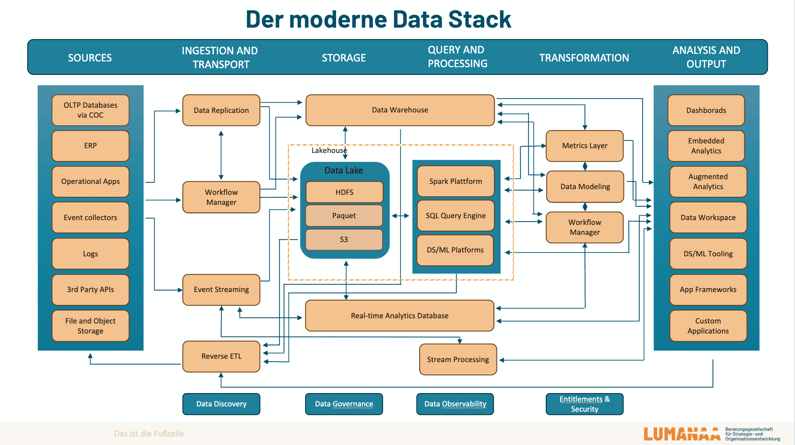
Abbildung 2: Übersicht über das Kunden Dashboard
Der moderne Data Stack bindet sowohl das Data Warehouse als auch den Data Lake ein und umfasst verschiedene Schichten. Ziel ist es, auf Basis der eingespeisten Daten (links in der Abbildung) konkrete Analysedaten (rechts in der Abbildung), beispielsweise zu den erwarteten Vertriebszahlen und anderen Prognosen, abzufragen. Daten werden dafür im Speicher gesammelt und sortiert, um dann zweckgebunden zur Verfügung gestellt zu werden. Dabei entstehen Data Pools, auf die die gesamte Organisation Zugriff haben, anstelle von Data Silos, auf die nur einzelne Business Units Zugriff haben.
Die Schichten des Data Stacks im Überblick:
- Datenquellen: beispielsweise ERP-Systeme, CRM-Daten, Hubspot, unstrukturierte Daten und andere externe Datenquellen
- Ingestion und Transport Layer: Daten werden in den Data Lake geladen, Möglichkeit für Time-Travel-Funktion zur Simulation der Vergangenheit (z. B. bei Machine Learning)
- Storage Layer: Effiziente Speicherung der Daten im Data Lake oder Data Warehouse auf privaten Servern oder in Cloud-Lösungen.
- Transformations-Layer: Daten werden kuratiert und in einen sinnvollen Kontext gesetzt, um die Fragen, die aus unterschiedlichen Bereichen des Business kommen, beantworten zu können
- Analyse-Layer: Analysedaten werden zur Entscheidungsfindung bereitgestellt
Durch den Aufbau eines modernen Data Stacks können Unternehmen sicherstellen, dass ihre Daten transparent und zugänglich sind, um fundierte Entscheidungen zu treffen und den Bullwhip-Effekt effektiv zu vermeiden.
Fallbeispiel Reiseapotheke: Wie sieht ein möglicher Output aus?
Die erste Abbildung zeigt eine Möglichkeit, wie die Daten aus dem Data Stack zweckgebunden zur Verfügung gestellt werden können, um datengestützte Entscheidungen zu ermöglichen.
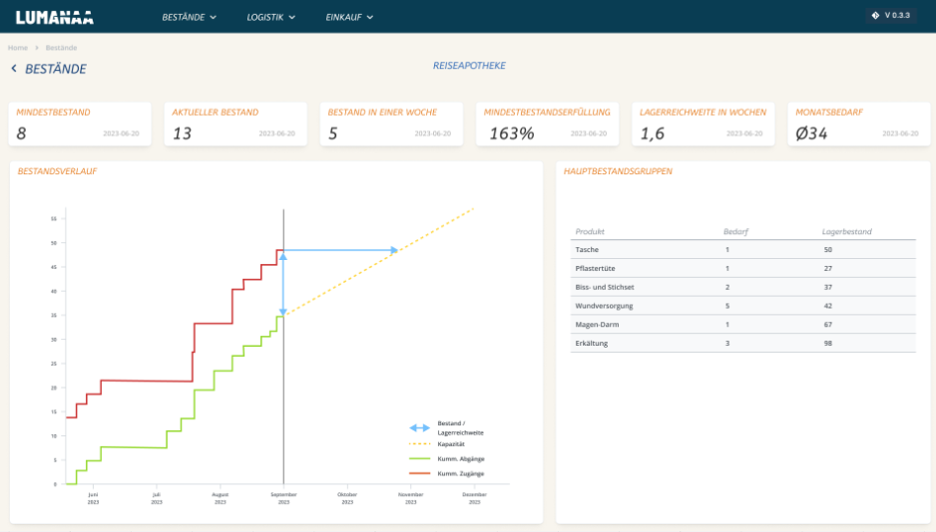
Abbildung 3: Umsatz und Auslastungsdashboard
In diesem Fallbeispiel wurde ein modernen Data Stack aufgebaut, um die Supply Chain für den Verkauf einer Reiseapotheke zu managen. Durch die eingespeisten Daten konnte das Einkaufsverhalten (rote Linie), mit den Absätzen des betreffenden Produkts (grüne Linie) im Graph verglichen werden. Die waagerechte blaue Linie verdeutlicht, wie lange der Bestand in die Zukunft reicht, wenn das Einkaufsverhalten auf Basis der Prognose gleich bleibt. Die senkrechte blaue Linie verdeutlicht die Höhe des Lagerbestands.
Rechts neben dem Graph wird angezeigt, welche Einzelprodukte in dem Produkt Reiseapotheke enthalten sind und wie der jeweilige Lagerbestand aussieht.
Die zweite Abbildung zeigt die Übersicht über das Kunden-Dashboard.
Fazit: Die Bedeutung datengestützter Entscheidungen in der Lieferkette
Datengestützte Entscheidungsfindung ist für Unternehmen in der komplexen Welt der Supply Chain von entscheidender Bedeutung. Insbesondere der Bullwhip-Effekt, der zu erheblichen Störungen in der Lieferkette führen kann, verdeutlicht die Notwendigkeit transparenter Daten und datengesteuerter Ansätze, um dieses Problem zu managen.
Der moderne Data Stack ermöglicht es Unternehmen, die Unsichtbarkeit und Intransparenz in der Lieferkette weitgehend aufzulösen und den Bullwhip-Effekt zu vermeiden. Auf Basis der verschiedenen Daten können zweckgebundene Analysen für einzelne Fragestellungen durchgeführt werden.
Das ermöglicht Data-Driven Decision Making (DDDM), also das Treffen von Entscheidungen, die auf objektiven Informationen basieren.
Insgesamt zeigt sich, dass datengestützte Entscheidungsfindung in der Supply Chain unerlässlich ist, um effektiv zu agieren und sich den Herausforderungen einer dynamischen Geschäftsumgebung zu stellen.
Für einen noch tieferen Einblick in das Thema datengestützte Entscheidungsfindungen in der Supply Chain steht hier unsere Case Study zum Download bereit.


 info@lumanaa.de
info@lumanaa.de